Developing Custom Functions for Medidata Rave
Writing Custom Functions in Medidata Rave Architect can be a frustrating experience. The editor provides the basics for entering and validating Custom Function code in C# but little more. So what are the alternatives?
Visual Studio
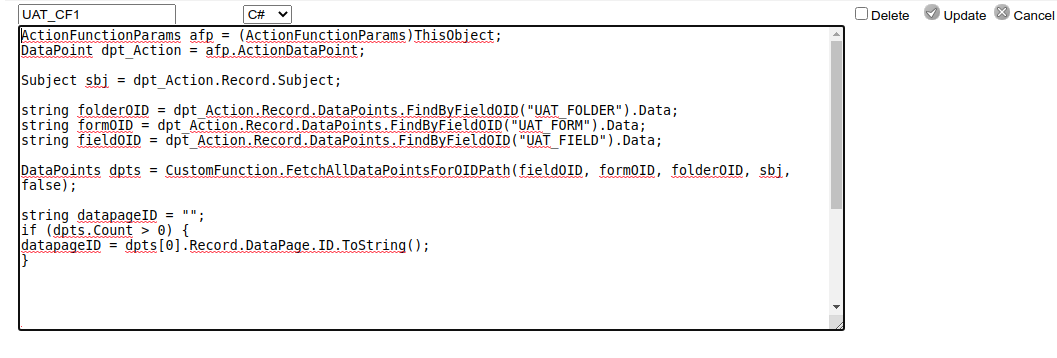
Many Custom Function programmers do not develop Custom Functions in Architect. Instead they rely on Visual Studio which provides line numbering, syntax highlighting and all the benefits of a modern source code editor. Properly configured with the Medidata Core Object DLL's Visual Studio can also provide syntax highlighting and intellisense for the Rave Core Object Model classes.
In the most basic usage a programmer would write their Custom Function code in Visual Studio and then cut and paste it into the Architect Custom Function edit window to validate and save the code.
Custom Function Debugger
Programmers with Visual Studio and access to the Custom Function Debugger and ROAD (Rave On A Disk) have the best possible experience since they can connect directly to a running Rave instance to debug and test Custom Functions. This setup is highly recommended for Custom Function programmers but it can be difficult to arrange access to ROAD.
What if you don't have Visual Studio?
The majority of Rave study builders do not have access to the Custom Function Debugger and cannot install Visual Studio on their computers and so are stuck with the basic Custom Function editor in Architect. If you want to develop Custom Functions of any complexity you will need a guide to the available classes and methods of the Rave Object Model such as DataPoint, Record and Subject. Happily, Medidata has published a list of allowed methods as part of the Custom Function documentation on learn.mdsol.com. This is recommended reading and can help you look up method signatures without having to rely on guesswork and scanning other Custom Functions for examples.
The TrialGrid Custom Function Editor
Organizations with access to TrialGrid may use our advanced version of the Custom Function editor. This includes many of the features of a programmers editor like Visual Studio:
- Syntax highlighting
- Line numbering
- Search/Replace
- Auto-formatting
- Undo/redo for editing
- Code folding
- Validation
- Autocomplete
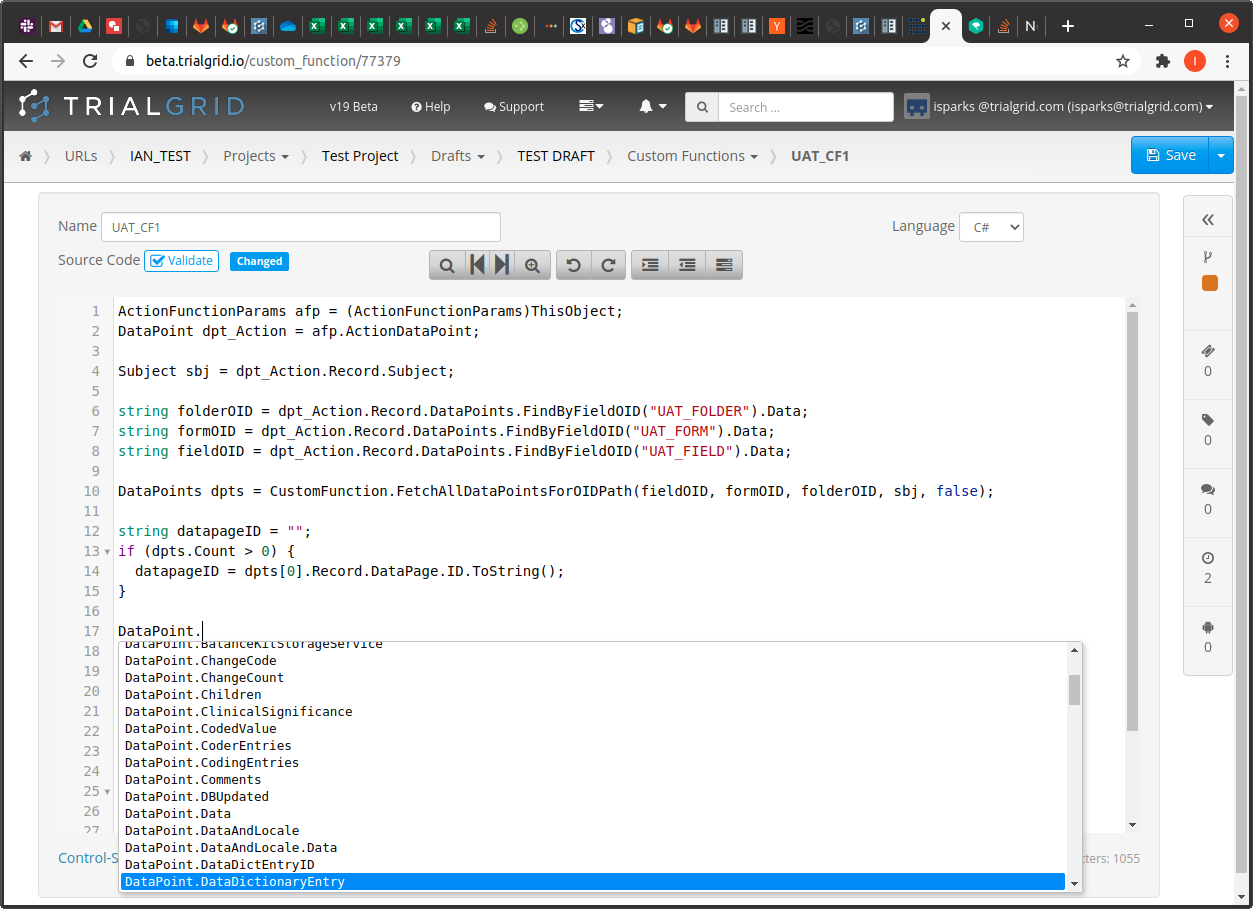
In the example above you can see Autocomplete showing the list of available methods for the DataPoint object type.
This isn't the same as the Intellisense you get with Visual Studio which is context-aware (i.e. it knows the types of variables and can provide autocomplete specific to that variable) but it reduces the need to consult the documentation to look up method signatures which is a big time saver.
Overall the TrialGrid Custom Function editor is a major step-up from the basic editor included with Rave Architect but for users that can install Visual Studio this is still the recommended approach.
Feature comparison
| |
Rave Architect |
TrialGrid | Visual Studio | Visual Studio with Core Objects DLL |
Visual Studio & Custom Function Debugger |
|---|---|---|---|---|---|
| Price | Rave License |
TrialGrid License |
Free (Install required) |
Rave License (Install Required) |
Rave License, ROAD License (Install Required) |
| Validation | Yes | Yes | Yes | Yes | Yes |
| Syntax Highlighting | - | Yes | Yes | Yes | Yes |
| Line Numbering | - | Yes | Yes | Yes | Yes |
| Code Formatting | - | Yes | Yes | Yes | Yes |
| Rave Autocomplete | - | Yes | - | Yes | Yes |
| Rave Intellisense | - | - | - | Yes | Yes |
| CF Debugging | - | - | - | - | Yes |
If you are interested in knowing more about how the TrialGrid Custom Function Editor can accelerate your Medidata Rave study build process please contact us!



