When you are working with Standard Libraries of Forms, Data Dictionaries, Edit Checks and other types of Medidata Rave
study design objects it is normal to have deviations from the standard defined by the matching object in the library.
For example, you might add or remove an entry from a Data Dictionary or you might change the question text of a
Field on a Form.
Some of these deviations from the library object are expected: A neonatal study may collect age in days or weeks rather
than in years for example, but some of these deviations may require review by a Standards Librarian or Standards
Manager.
Old Standards Compliance Workflow
Since 2016 the TrialGrid system has had a review workflow for differences from the Standard Library. We call this
the Standards Compliance Workflow. Up until now, an object which deviated from the standard would be flagged as
an unexplained deviation. The study builder or programmer could request approval for the object and this would notify
a Standards Librarian to review the object and approve or deny the deviation. If the object was changed again, any
approval would be removed, rather like an investigator signature in Rave EDC, and the workflow would return to
Unexplained and require re-approval.
New Standards Compliance Workflow
This week we released an update to our standard compliance which uses this workflow on a per-change
basis. Previously approvals were requested and granted on a per-object basis e.g.
- "This Form has deviated from standard please approve".
Now approvals are per-change this single request might now be two individual requests:
- "The Field AGE in Form DM now has a FixedUnit of 'weeks'. Please approve."
- "The AGE_UNITS Field in Form DM has been removed. Please approve"
With the new system the Standard Librarian can review each change individually and approve/deny it. The overall
Form status would be the worst status (Denied or Unexplained) with the Form getting approved status only if all the
deviations had been approved.
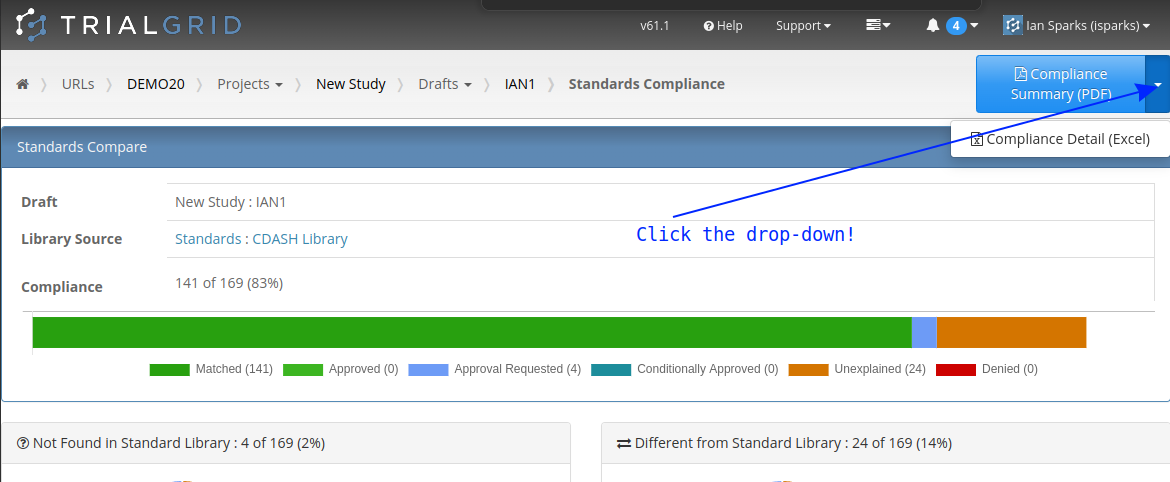
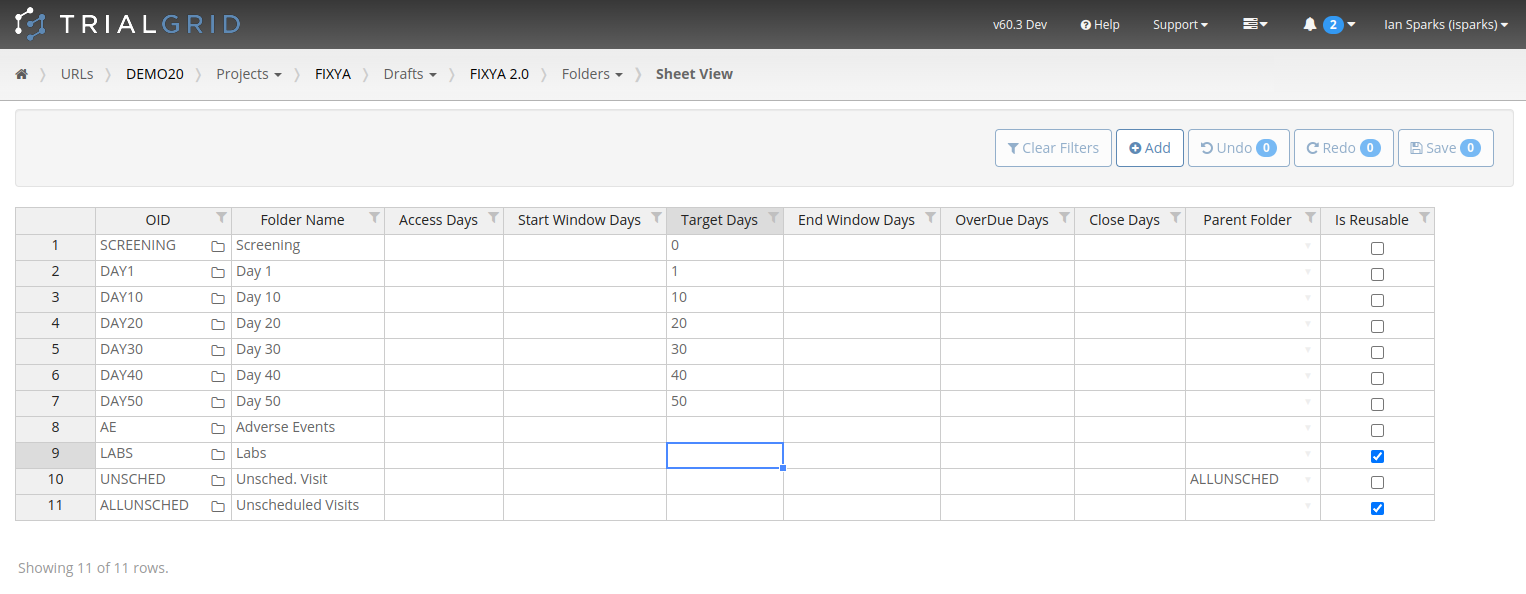
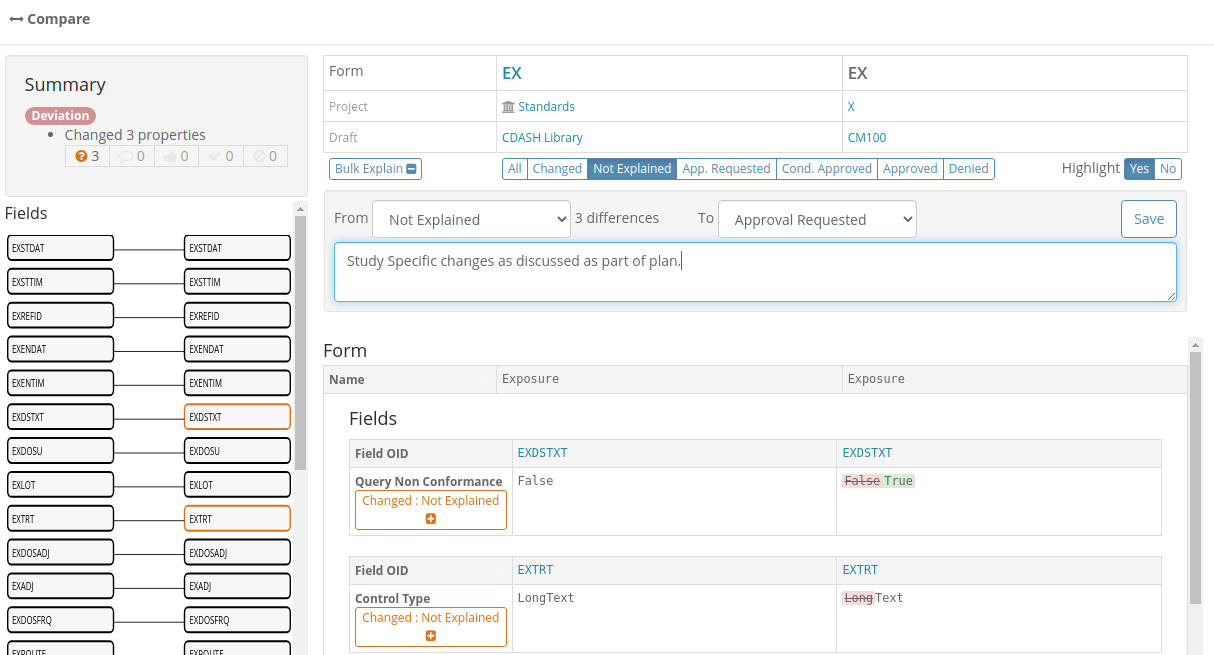
In this screenshot we see the comparison between a Form and its equivalent in the standard library filtered to just
show the differences. We can see the differences have different explanation states as denoted by their colors:
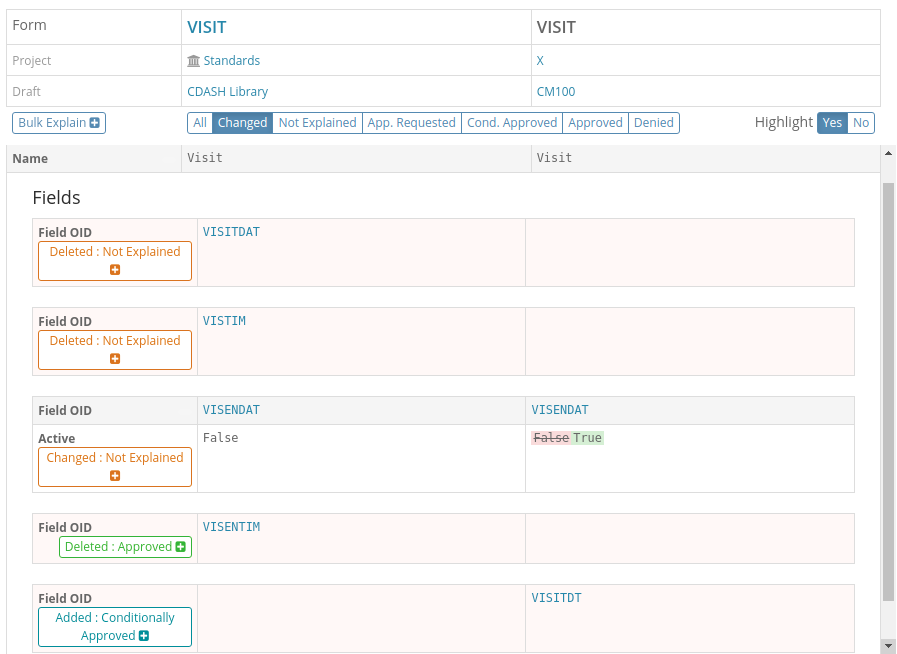
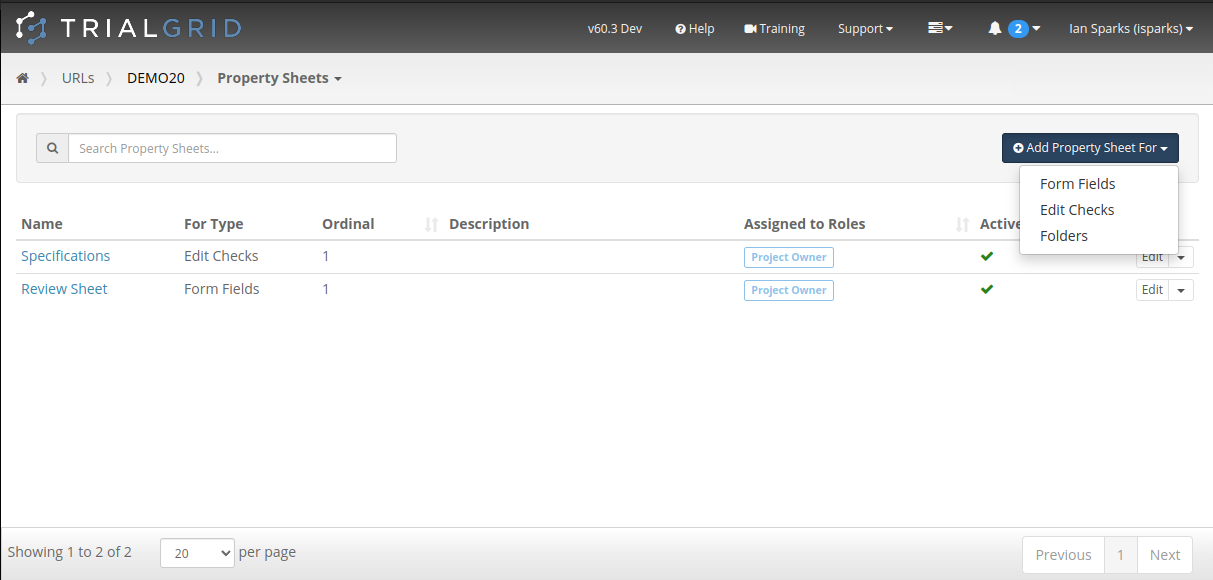
The counts of differences and their workflow states are also show in listings as shown in this Form list:
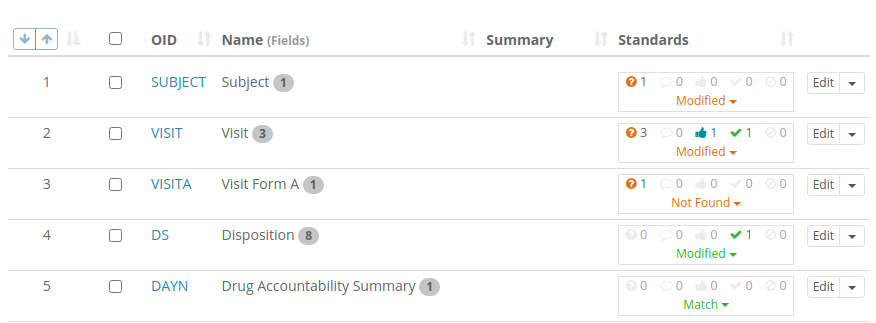
These listings can be filtered to show only items where explanation is required or where approval has been requested
to make it easy for Study Builders or Standard Librarians to find objects requiring their attention.
Advantages of new approach
This new approach improves dialog between Study Builder and Standards Librarian because each change can be individually
discussed. The explanations, requests for approval and approvals are all stored at the Project level so if a change
in a Field definition is approved in Draft1 then this exact change does not have to be re-approved in Draft 2 and Draft 3
which significantly reduces the workload for both Study Builders and Standards Librarians.
With these fine-grained approvals it is easier to spot trends and gather metrics on deviations from the standard
library so that the usage instructions for library objects can be improved. The TrialGrid system also has a number of
features which allow expected deviations to be encoded in the library. These expected deviations do not have to be
explained, they are automatically approved, again improving the efficiency of the team.
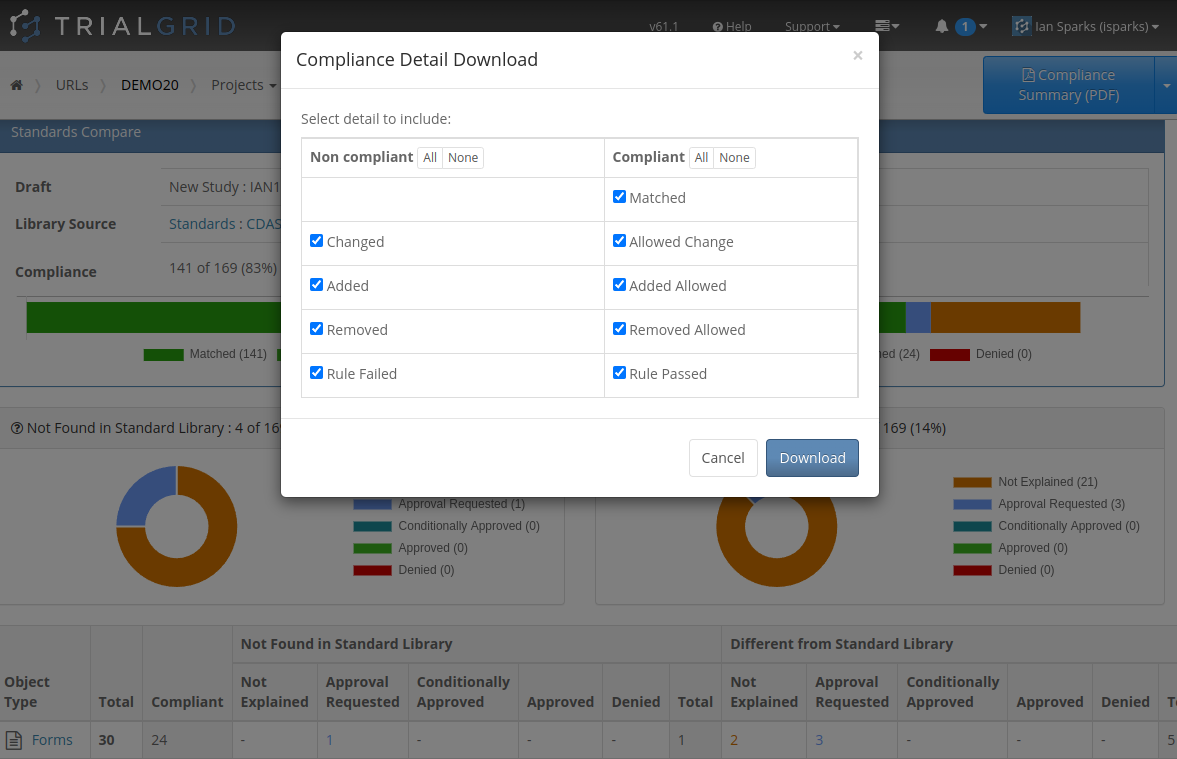
Batch Approval
One consequence of having per-difference approvals is that the number of changes to be reviewed is increased. Previously
there might be a request to review five Forms, under the new system this might be a request to review thirty changes
across those same five Forms. New features of the standards approval listings allow Standard Librarians to search
and filter these requests and approve/deny them in batch.
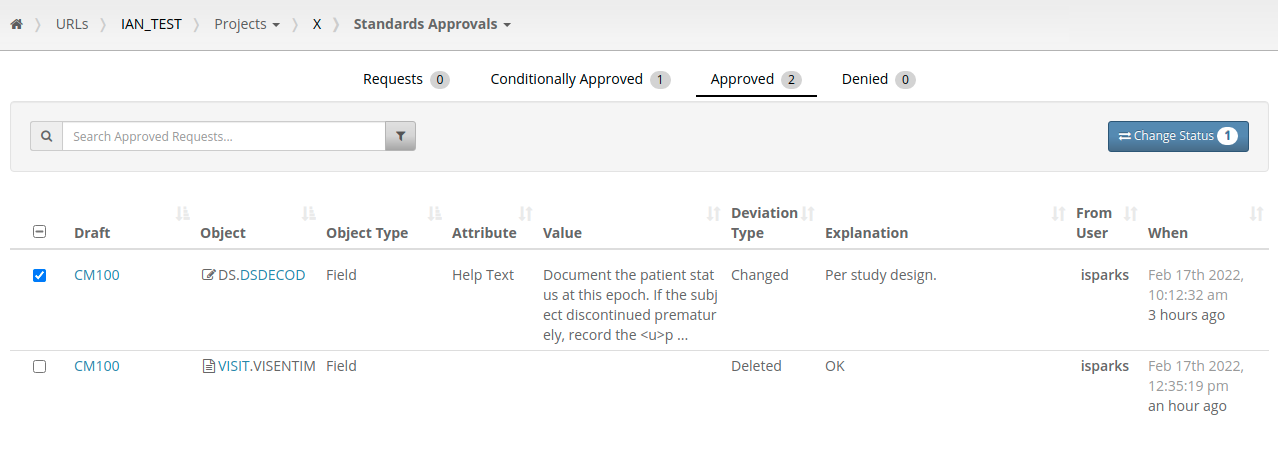
Similar functionality is available for study builders requesting approval for changes to an object. If they make
changes to a Form they can request approval for those changes individually or make a request for all the changes
in a batch.
Conditional Approval
Our old workflow process had four states:
-
Unexplained - A change has been made but the Study Builder has not yet requested approval for it (they may still be
working on it with further changes expected)
-
Approval Requested - The Study Builder has finalized their work (for now) and is requesting approval for the deviation
from the standard.
-
Approved - A Standards Librarian has reviewed the deviation and approved it.
-
Denied - A Standards Librarian has reviewed the deviation and has rejected it, signalling that the
Study Builder should change the object design before requesting approval again or revert it to the standard.
The new process adds a new state Conditionally Approved which is a signal that the Standards Librarian is accepting
this deviation for now but will want to review this decision later. This is useful where the deviation is the addition
of a new object such as a Form or an Edit Check which does not exist in the library. There can be no detailed comparison
between this new object and the library because it does not exist in the library. The Standards Librarian may want to
give a go-ahead to allow the new Form or Edit Check to exist but re-review it at a later stage to ensure that it is
compliant with the principles of the library when it is finalized.
Summary
The use of Standard Libraries is highly recommended to improve the speed and efficiency of study build but
deviations from the standard are inevitable. The ability to review and approve deviations and to capture detailed
information about the types of deviations and reasons for them is important for continuous improvement of the
Libraries and team efficiency.
The TrialGrid system can be used for Medidata Rave study build activities where this standards-compliance feedback is
available in real-time or it can be used after study build is complete to perform comparisons between the library
and the as-built study in a postmortem or lessons-learned exercise.
Either way, an organization will gain insight into how and why their study builds deviate from their library standards.