5x improvement in TrialGrid ALS import performance
Fast application performance is essential to a good user experience, so at TrialGrid we've been careful to provide the best experience that we can. Most activities in TrialGrid are instant, but sometimes a process like uploading an Architect Loader Spreadsheet might take a while. TrialGrid performs tasks like this in the background, so that users aren't blocked while waiting for the process to finish and can work elsewhere in TrialGrid until they are notified that the task has been completed.
Uploading Architect Loader Spreadsheets in the background is useful, but we still want to ensure that they load as fast as possible so that users can start running Diagnostics, assessing Standards Compliance and improving the Study Build. In this post I'll describe how I made TrialGrid's upload process run 5x faster so that even the largest ALS files should load in less than a minute!
Test file
To measure the hoped-for improvements in performance I used a large Architect Loader Spreadsheet:
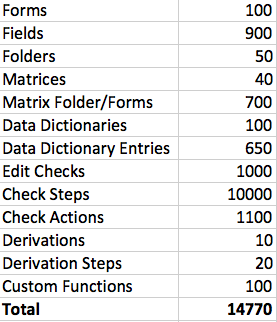
The ALS file is 84Mb uncompressed and 2Mb when compressed into a zip archive file.
Baseline
Running on my local machine I measured the time to upload the uncompressed test file: 160 seconds
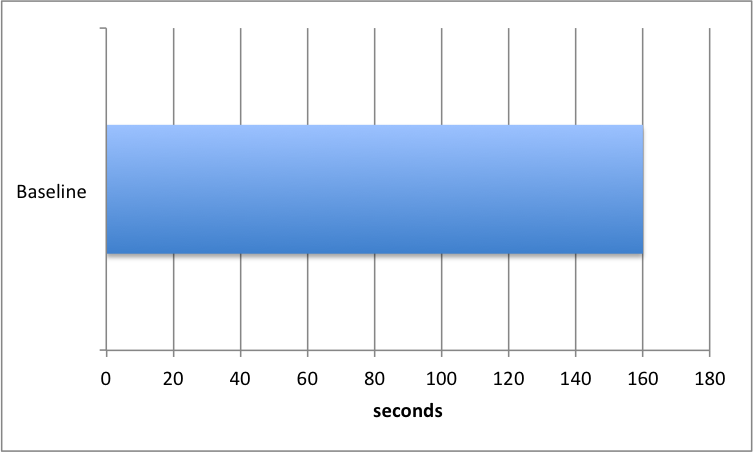
For such a large ALS that's not a bad starting point. But lets see if we can do even better....
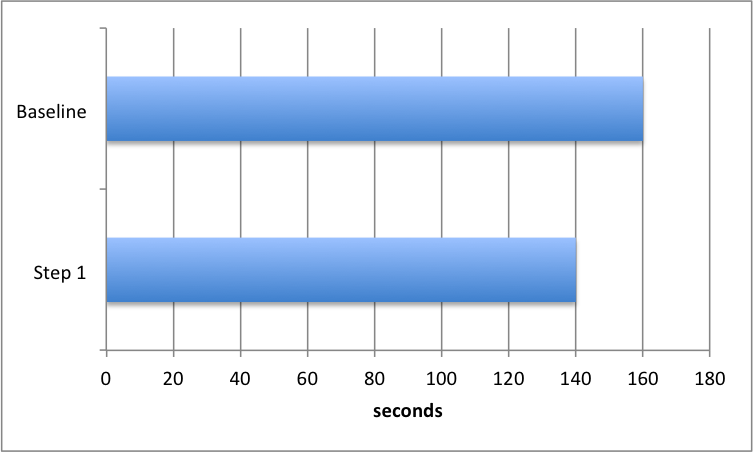
Step 1: Eliminate intermediate saves to the database
Our ALS import process has several steps to create the study in our database, several of which were saving records to the database. For example, for each Edit Check rows would be inserted into database tables for the check itself, its check steps and its actions. In a later step we generated the cql version of the check and saved that to the database. Then we would look at the Step Ordinals and if there were gaps we would renumber them and save those records to the database again (eg. steps with ordinals 1, 4, 8, 10 would be renumbered to 1, 2, 3, 4). Each call to the database is fast, but when you are doing lots of them the time adds up quickly. My first optimization was to only save the records to the database at the end of upload processing, and not save them in the intermediate steps. This reduced the upload time by 20 seconds, to 140 seconds on my local machine.
Step 2: Fingerprint calculation
For our Standards Compliance features we generate a 'fingerprint' for each Form, Field, Data and Unit Dictionary, Edit Check, Derivation and Custom Function. This fingerprint is calculated from the properties of the object which are relevant to Standards Compliance. In the case of Data Dictionaries that's the Data Dictionary Name and then for each entry in the dictionary its User Data String, Coded Value and Specify value. We calculated the fingerprint by generating a YAML representation of the object and then taking the md5 hash value of the YAML representation. We used YAML because we also use that to display differences the version of an object in a Library and in a Project
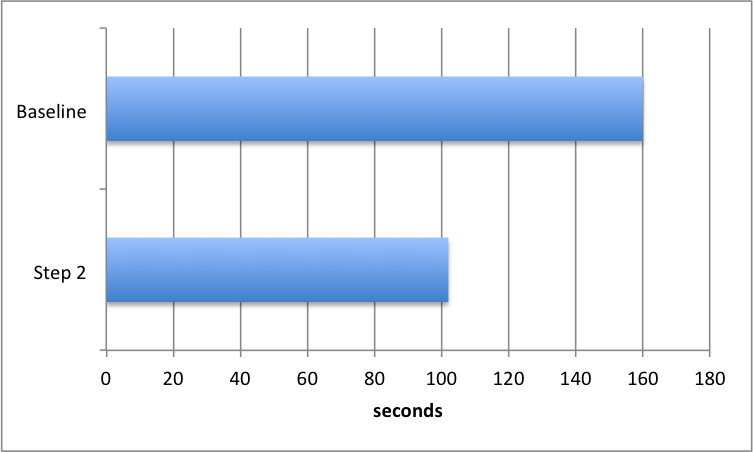
However YAML is not a particularly efficient structure to generate, so while it's OK to keep it for displaying the differences between 2 versions of an object, it is time-consuming to calculate it for many objects. Switching to a JSON representation of the object and then taking the md5 hash of that reduced the time to upload to 102 seconds.
Step 3: CQL generation
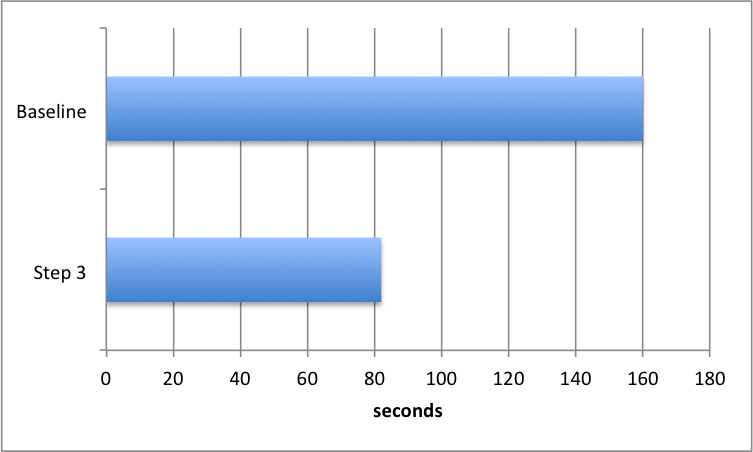
For our Edit Check editor we need to generate the Clinical Query Language (CQL) format of the check from the Rave Check Steps (CQL is TrialGrid's human-readable format for creating Edit Checks). The import process was doing this by reading the newly created Check Steps from the database and then generating the CQL format. But during the import we already have the Check Steps in memory in the import process itself, and by using the in-memory objects the time to upload came down to 82 seconds.
Step 4: Bulk database updates
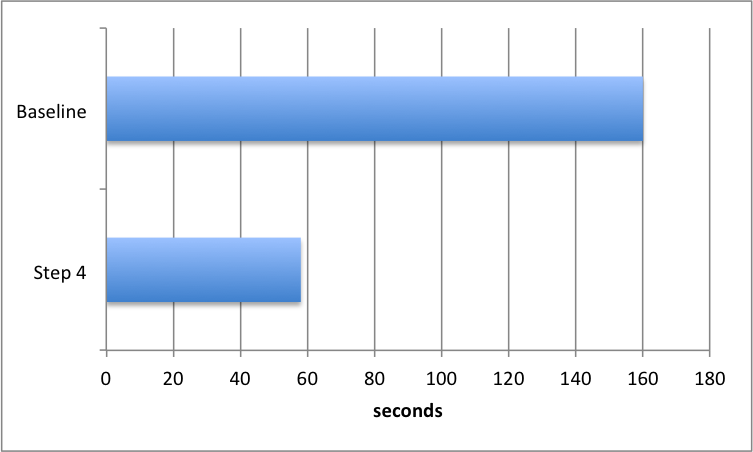
In Step 1 I moved database saves to the end of processing. However each object was being saved separately, resulting in many thousands of database saves. SQL can perform bulk updates of objects in one statement so by combining updates I could reduce the number of saves to one for each object type (Form, Field, etc). The upload time was now down to 58 seconds.
Step 5: Database fingerprint functions
Using JSON in place of YAML in Step 2 helped reduce upload time, but I felt we could go further by moving the fingerprint calculation into the database, using database functions. While there are arguments against placing business logic in the database, the fingerprint calculation isn't business logic in itself - it is used to assess Standards Compliance between objects, but calculating the fingerprint is something we want to happen every time an object is created or updated, so placing it in the database makes sense. It helps with performance because of data locality - the processing and data are co-located.
This step was the most complicated to work through, but with good results: upload time down to 23.5 seconds!
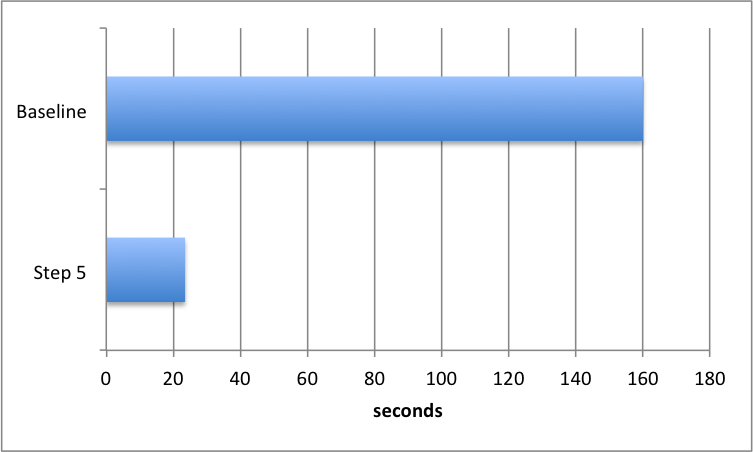
Real-world performance
The steps above showed that on my local development machine the time to upload this large ALS was slashed from 160 seconds to 23.5 seconds. But now I needed to prove that in the real-world deployment of TrialGrid we would see similar results. The baseline measurement on our beta site for loading the uncompressed, 84Mb, file into TrialGrid was 180 seconds - a little longer than on my local machine because of the time taken to transfer the file over the network. After deploying the optimized code the same upload was only 38 seconds, a huge improvement. Finally I tested uploading the compressed version, which took 27 seconds - faster again because less data needed to be transferred over the network.
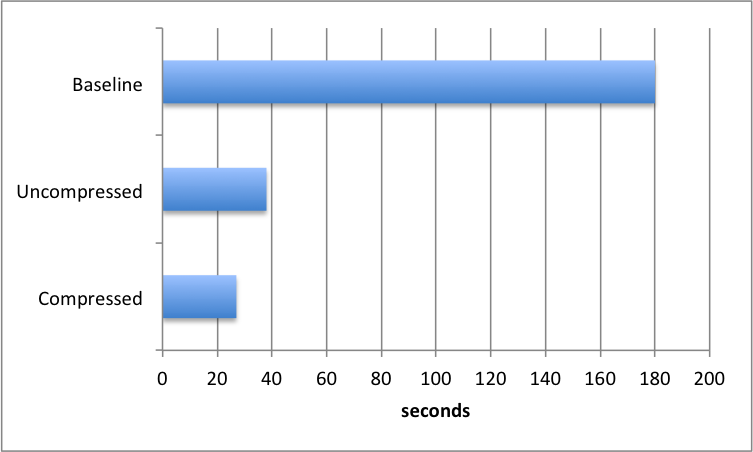
We were delighted with these results and they're now live on our beta site. Uploading Architect Loader Spreadsheets has never been faster!
Interested in finding out more? Contact us for more information.